Recent advances in voice cloning and lip synchronization models have enabled Synthesized Audiovisual Forgeries (SAVFs), where both audio and visuals are manipulated to mimic a target speaker. This significantly increases the risk of misinformation by making fake content seem real. To address this issue, existing methods detect or localize manipulations but cannot recover the authentic audio that conveys the semantic content of the message. This limitation reduces their effectiveness in combating audiovisual misinformation. In this work, we introduce the task of Authentic Audio Recovery (AAR) and Tamper Localization in Audio (TLA) from SAVFs and propose a cross-modal watermarking framework to embed authentic audio into visuals before manipulation. This enables AAR, TLA, and a robust defense against misinformation. Extensive experiments demonstrate the strong performance of our method in AAR and TLA against various manipulations, including voice cloning and lip synchronization.
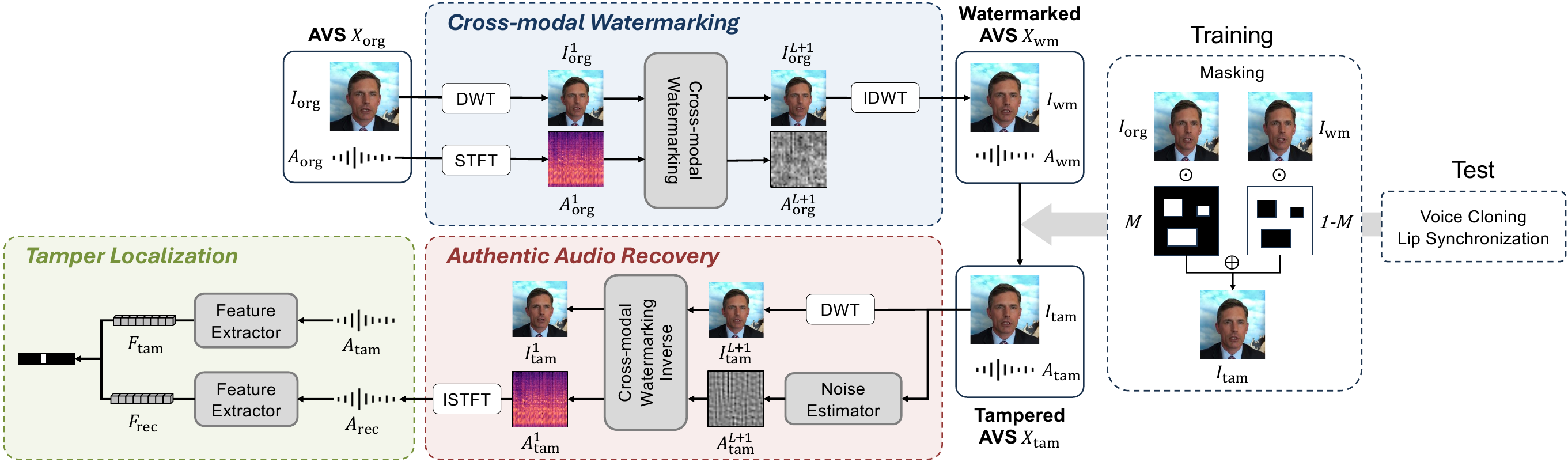
Overview of Our Models The framework comprises three main processes: cross-modal watermarking (CMW), authentic audio recovery, and tamper localization. In the CMW process, CMW embed the authentic audio within a visual frame. For authentic audio recovery, noise estimators predict the transformed audio output from watermarked visual frame, enabling the inverse CMW to recover the authentic audio embedded in the visual frame. Finally, in tamper localization, we compute feature maps for both the recovered and tampered audio to generate a score that identifies the tampered regions.
In this work, we aim to recover authentic audio and localize temporally tampered regions in Synthesized Audiovisual Forgeries (SAVFs), which are generated via voice cloning and lip synchronization. Specifically, our objectives are: (1) to reconstruct the original audio from tampered AVS inputs and (2) to detect time intervals ${(t^i_\mathrm{start}, t^i_\mathrm{end})}_{i=1}^N$ corresponding to manipulated audio segments. To address the tasks of AAR and TLA, we propose a watermarking-based approach as follows: Given an original AVS $X_\text{org} = (I_\text{org}, A_\text{org})$, we imperceptibly embed the authentic audio $A_\text{org}$ into the visual frame $I_\text{org}$ to produce a watermarked AVS $X_\text{wm} = (I_\text{wm}, A_\text{org})$. After potential tampering (e.g., lip synchronization or voice cloning), we obtain $X_\text{tam} = (I_\text{tam}, A_\text{tam})$. For Authentic Audio Recovery (AAR) and Tamper Localization in Audio (TLA), our method reconstructs $A_\text{rec}$ from $I_\text{tam}$ and compares it with $A_\text{tam}$ to identify manipulated regions.
For the watermarking process, we employ Cross-Modal Watermarking (CMW), which consists of a series of Invertible Neural Network (INN) blocks. INNs have the distinctive property of reversibility, allowing the original inputs to be exactly recovered from their outputs. Specifically, given an original visual frame and its corresponding audio, CMW embeds the audio into the visual domain by transforming both modalities through a stack of INN blocks. This process produces a watermarked visual that imperceptibly carries the audio information. Crucially, the reversible nature of INNs enables us to later recover the embedded audio from the (potentially tampered) visual input, thereby supporting Authentic Audio Recovery (AAR). After performing AAR, we localize tampered regions by comparing the recovered and tampered audio in a semantic feature space. Instead of directly comparing raw audio signals, which are sensitive to noise and recovery artifacts, we extract high-level audio features and compute cosine similarity at each timestep. This feature-level comparison enables robust and precise tamper localization by focusing on semantic differences rather than low-level signal variations.

Comparison of Different Audio Tamper Localization Methods on the HDTF Dataset. Tampering simulation uses two methods: AS-inserting a different audio segment into the parts of original audio and VS-modifying parts of the audio with voice generated by voice cloning model. Localization metrics include IoU, AP, and AUC, while SNR and PESQ measure recovered audio quality, respectively. SSIM and PSNR measure video quality. WM and CM refer to watermarking and cross-modal techniques.
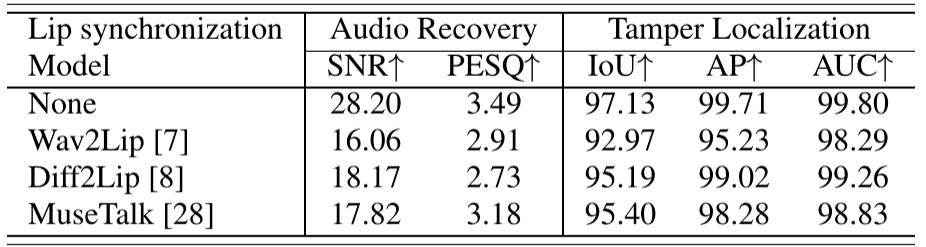
Comparison of Different Lip Synchronization Methods. We evaluate our model's robustness against three lip synchronization methods. As shown in Table, performance is highest without manipulation, preserving the embedded watermark. Although lip synchronization introduces some degradation, speech remains intelligible and scores stay relatively high. Notably, TLA accuracy consistently exceeds 90%, demonstrating the model’s effectiveness and reliability under adversarial conditions.

Qualitative Examples The watermarked frames and recovered audio closely resemble the original AVS, ensuring imperceptible embedding and authentic audio recovery.
lorem-ipsum

